This article explains how to use Nexa full node Command Line Interface (CLI) to extract JSON data into Python, and plot it using the pandas and matplotlib python libraries. Nexa is a bitcoin-like Proof of Work (PoW) -based blockchain that has massive scalability and smart-contracts. This article focuses on extracting the raw full-node data into JSON and parsing it using python on a windows machine.
Motivation
The aim is to provide a straightforward approach to obtaining raw data directly from the Nexa blockchain, structuring it effectively, and creating datasets suitable for time-series analysis. Thus, providing a simple framework to build upon, in order to work with Nexa On-Chain data using Python. (See the end of the article for a timeseries plot of data collected from a 1000-block interval)
Content
· Part 1: Installing and connecting to Nexa full node.
· Part 2: Pull block and transaction data and save as json.
· Part 3: Read json-file, convert data into timeseries, then plot time-series data.
Prerequesites
Windows 10
Python 3
Nexa full node
Pandas
Matplotlib
Part 1: Installing and connecting to the full node
- Start the full node, then the blockchain synchronization will start. This can take some time. After it is finished, close the full node
- Locate the configuration file (CONF-file). This is usually located under users/myuser/AppData/Roaming/nexa. Open the file using a simple text editor. Add the following to the CONF-file:
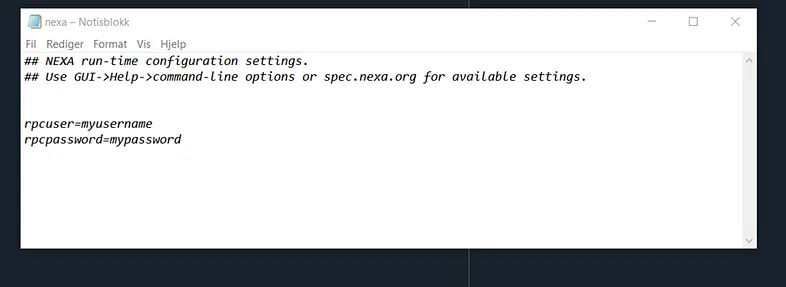
“myusername” and “mypassword” are arbitrary. You are free to write whatever you like for your rpcuser and rpcpassword .
- Open the cmd prompt. Locate the path of nexad.exe

- Copy address path, paste the path in cmd terminal after the command cd. Example: cd C:\Program Files\Nexa\daemon
- Now, start nexad.exe by writing nexad in the cmd terminal. This process can take about a minute. This will start nexad: A Nexa full node daemon that runs without displaying any graphical interface.

- You might also get a windows defender pop-up warning. Click “Allow”. Now you are up and running with connection to the full node.
The following script will give you an overview over the Nexa CLI commands:
import subprocess
def run_shell_command(command):
process = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
output, error = process.communicate()
if output:
return output.decode("utf-8")
else:
return ""
if __name__ == "__main__":
command = "C:/Program Files/Nexa/daemon/nexa-cli -rpcpassword=mypassword -rpcuser=myusername help"
output = run_shell_command(command.split())
print(output)
The next part of this article (part 2) uses the following commands to retrieve data from the Nexa full node into a json file:
getblockcount— Retrieves the total number of blocks in the blockchain (i.e., the height of the latest block).getblockhash <block_height>— Returns the hash of the block at the specified block height.getblock <block_hash> 1— Retrieves detailed information about a block using its hash. The1parameter specifies that the result should be verbose, including detailed information about transactions in the block.getrawtransaction <txid> 1— Retrieves detailed information about a specific transaction using its transaction ID (txid). The1parameter specifies that the result should be in a detailed, JSON-encoded format.
Output
The output of the nexa-cli help
== Blockchain ==
dumputxoset "filename"
evicttransaction "txid"
getbestblockhash
getblock hash_or_height ( verbosity ) ( tx_count )
getblockchaininfo
getblockcount
getblockhash index
getblockheader hash_or_height ( verbose )
getblockstats hash_or_height ( stats )
getchaintips
getchaintxstats ( nblocks blockhash )
getdifficulty
getorphanpoolinfo
getraworphanpool
getrawtxpool ( verbose ) (id or idem)
getrawtxpool ( verbose ) ( id or idem)
gettxout "txidem" n ( includetxpool )
gettxoutproof ["txid",...] ( blockhash )
gettxoutproofs ["txid",...] ( blockhash )
gettxoutsetinfo
gettxpoolancestors txid (verbose)
gettxpooldescendants txid (verbose)
gettxpoolentry txid
gettxpoolinfo
saveorphanpool
savetxpool
scantokens <action> ( <scanobjects> )
verifychain ( checklevel numblocks )
verifytxoutproof "proof"
== Control ==
getinfo
help ( "command" )
stop
uptime
== Electrum ==
getelectruminfo
== Generating ==
generate numblocks ( maxtries )
generatetoaddress numblocks address (maxtries)
== Mining ==
genesis
getblocktemplate ( "jsonrequestobject" )
getblockversion
getminercomment
getminingcandidate
getmininginfo
getminingmaxblock
getnetworkhashps ( blocks height )
prioritisetransaction <tx id or idem> <priority delta> <fee delta>
setblockversion blockVersionNumber
setminercomment
setminingmaxblock blocksize
submitblock "hexdata" ( "jsonparametersobject" )
submitminingsolution "Mining-Candidate data" ( "jsonparametersobject" )
validateblocktemplate "hexdata"
== Network ==
addnode "node" "add|remove|onetry"
capd
clearbanned
clearblockstats
disconnectnode "node"
expedited block|tx "node IP addr" on|off
getaddednodeinfo dns ( "node" )
getconnectioncount
getnettotals
getnetworkinfo
getpeerinfo [peer IP address]
gettrafficshaping
listbanned
ping
pushtx "node"
savemsgpool
setban "ip(/netmask)" "add|remove" (bantime) (absolute)
settrafficshaping "send|receive" "burstKB" "averageKB"
== Rawtransactions ==
createrawtransaction [{"outpoint":"id","amount":n},...] {"address":amount,"data":"hex",...} ( locktime )
decoderawtransaction "hexstring"
decodescript "hex"
enqueuerawtransaction "hexstring" ( options )
fundrawtransaction "hexstring" includeWatching
getrawblocktransactions
getrawtransaction "tx id, idem or outpoint" ( verbose "blockhash" )
getrawtransactionssince
sendrawtransaction "hexstring" ( allowhighfees, allownonstandard, verbose )
signrawtransaction "hexstring" ( [{"outpoint":"hash","amount":n,"scriptPubKey":"hex","redeemScript":"hex"},...] ["privatekey1",...] sighashtype sigtype )
validaterawtransaction "hexstring" ( allowhighfees, allownonstandard )
== Util ==
createmultisig nrequired ["key",...]
estimatefee nblocks
estimatesmartfee nblocks
get
getaddressforms "address"
getstat
getstatlist
issuealert "alert"
log "category|all" "on|off"
logline 'string'
set
validateaddress "address"
validatechainhistory [hash]
verifymessage "address" "signature" "message"
== Wallet ==
abandontransaction "txid" or "txidem"
addmultisigaddress nrequired ["key",...] ( "account" )
backupwallet "destination"
consolidate ("num" "toleave")
dumpprivkey "nexaaddress"
dumpwallet "filename"
encryptwallet "passphrase"
getaccount "address"
getaccountaddress "account"
getaddressesbyaccount "account"
getbalance ( "account" minconf includeWatchonly )
getnewaddress ("type" "account" )
getrawchangeaddress
getreceivedbyaccount "account" ( minconf )
getreceivedbyaddress "address" ( minconf )
gettransaction "txid or txidem" ( includeWatchonly )
getunconfirmedbalance
getwalletinfo
importaddress "address" ( "label" rescan p2sh )
importaddresses [rescan | no-rescan] "address"...
importprivatekeys [rescan | no-rescan] "nexaprivatekey"...
importprivkey "nexaprivkey" ( "label" rescan )
importprunedfunds
importpubkey "pubkey" ( "label" rescan )
importwallet "filename"
keypoolrefill ( newsize )
listaccounts ( minconf includeWatchonly)
listactiveaddresses
listaddressgroupings
listlockunspent
listreceivedbyaccount ( minconf includeempty includeWatchonly)
listreceivedbyaddress ( minconf includeempty includeWatchonly)
listsinceblock ( "blockhash" target-confirmations includeWatchonly)
listtransactions ( "account" count from includeWatchonly)
listtransactionsfrom ( "account" count from includeWatchonly)
listunspent ( minconf maxconf ["address",...] )
lockunspent unlock [{"txidem":"txidem","vout":n},...]
move "fromaccount" "toaccount" amount ( minconf "comment" )
removeprunedfunds "txidem"
sendfrom "fromaccount" "toaddress" amount ( minconf "comment" "comment-to" )
sendmany "fromaccount" {"address":amount,...} ( minconf "comment" ["address",...] )
sendtoaddress "address" amount ( "comment" "comment-to" subtractfeefromamount )
setaccount "address" "account"
signdata "address" "msgFormat" "message"
signmessage "address" "message"
token [info, new, mint, melt, balance, send, authority, subgroup, mintage]
== Zmq ==
getzmqnotifications
Great, you are now running the nexa-cli from python.
Part 2: Pull blockchain data and save as JSON
In this part, we will use the nexa-cli from python to pull data directly from the Nexa full node on our machine and copy it into JSON files.
The following script is designed to retrieve data from the Nexa blockchain using the nexa-cli command-line tool. It fetches data of the latest n blocks and its transactions in parallel, leveraging Python’s concurrent.futures module to speed up data retrieval. The script then saves this data to JSON files.
The library requirements for the next two scripts are: pandas, matplotlib
Main Execution Flow
· Initialize CLI Connection: Sets up the NexaCLI instance with the required parameters (cli_path, rpc_user, rpc_password).
· Fetch Latest Blocks: Calls get_latest_n_blocks to retrieve data for the latest n blocks using parallel processing.
· Save Block Data: Converts the block data to a DataFrame and saves it to a JSON file.
· Fetch All Transactions: Retrieves all transactions for the fetched blocks using parallel processing.
· Save Transaction Data: Saves the transaction data to a JSON file.
import subprocess
import json
import pandas as pd
from concurrent.futures import ProcessPoolExecutor, as_completed
class NexaCLI:
def __init__(self, cli_path, rpc_user, rpc_password):
self.cli_path = f'"{cli_path}"'
self.rpc_user = rpc_user
self.rpc_password = rpc_password
def run_command(self, command):
full_command = f"{self.cli_path} -rpcuser={self.rpc_user} -rpcpassword={self.rpc_password} {command}"
try:
result = subprocess.run(full_command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True, shell=True)
if result.stdout:
return result.stdout.strip()
elif result.stderr:
print(f"Error: {result.stderr.strip()}")
return ""
except Exception as e:
print(f"Exception occurred: {e}")
return ""
def get_latest_block_height(cli):
# Get the latest block height
command = "getblockcount"
output = cli.run_command(command)
if output.isdigit():
return int(output.strip())
else:
print(f"Failed to retrieve block count: {output}")
return None
def get_block_data(cli, block_height):
command = f"getblockhash {block_height}"
block_hash = cli.run_command(command).strip()
if not block_hash:
print(f"Failed to retrieve block hash for height {block_height}")
return {}
command = f"getblock {block_hash} 1"
block_data_output = cli.run_command(command)
try:
block_data = json.loads(block_data_output)
except json.JSONDecodeError as e:
print(f"JSONDecodeError for block {block_height}: {e}")
print(f"Command output: {block_data_output}")
return {}
return {block_height: block_data}
def get_transaction_data(cli, txid):
command = f"getrawtransaction {txid} 1"
output = cli.run_command(command)
if "error code: -5" in output:
print(f"getrawtransaction failed for {txid}, transaction might not be indexed or is not in the mempool.")
return None
if not output:
print(f"Error: No output for transaction {txid}")
return None
try:
transaction_data = json.loads(output)
except json.JSONDecodeError as e:
print(f"JSONDecodeError for transaction {txid}: {e}")
print(f"Command output: {output}")
return None
return transaction_data
def get_latest_n_blocks(cli, n, num_processes=None):
latest_block_height = get_latest_block_height(cli)
if latest_block_height is None:
return {}
if n > latest_block_height + 1:
print(f"Warning: Requested {n} blocks, but only {latest_block_height + 1} are available. Adjusting to {latest_block_height + 1}.")
n = latest_block_height + 1
block_heights = [latest_block_height - i for i in range(n)]
print(f"Starting block data retrieval with {num_processes} parallel processes...")
blocks_dict = {}
with ProcessPoolExecutor(max_workers=num_processes) as executor:
futures = {executor.submit(get_block_data, cli, block_height): block_height for block_height in block_heights}
for i, future in enumerate(as_completed(futures)):
block_data = future.result()
blocks_dict.update(block_data)
# Print progress every 10 iterations
if (i + 1) % 10 == 0 or (i + 1) == len(block_heights):
percentage = ((i + 1) / len(block_heights)) * 100
print(f"Retrieved block {list(block_data.keys())[0]} ({i + 1}/{len(block_heights)}) - {percentage:.2f}% complete")
return blocks_dict
def get_all_transactions(cli, blocks_dict, num_processes=None):
txids = [txid for block_data in blocks_dict.values() for txid in block_data.get('txid', [])]
print(f"Starting transaction data retrieval with {num_processes} parallel processes...")
transactions_data = []
with ProcessPoolExecutor(max_workers=num_processes) as executor:
futures = {executor.submit(get_transaction_data, cli, txid): txid for txid in txids}
for i, future in enumerate(as_completed(futures)):
tx_data = future.result()
if tx_data:
transactions_data.append(tx_data)
# Print real-time progress
percentage = ((i + 1) / len(txids)) * 100
if i % 10 == 0: # Print every 10 iterations
print(f"Processed transaction ({i + 1}/{len(txids)}) - {percentage:.2f}% complete")
return transactions_data
def save_block_data(df_blocks, save_json=False):
if save_json:
json_file_name = "nexa_last_blocks.json"
df_blocks.to_json(json_file_name, orient='records')
print(f"Block data saved to {json_file_name}")
def save_transaction_data(transactions_data, save_json=False):
if save_json:
json_file_name = "nexa_transactions.json"
with open(json_file_name, "w") as f:
json.dump(transactions_data, f, indent=4)
print(f"Transaction data saved to {json_file_name}")
if __name__ == "__main__":
cli_path = "C:/Program Files/Nexa/daemon/nexa-cli"
rpc_user = "myusername"
rpc_password = "mypassword"
cli = NexaCLI(cli_path, rpc_user, rpc_password)
n_blocks = 100
num_processes = 4 # You can adjust this number based on your system's capabilities
blocks_dict = get_latest_n_blocks(cli, n_blocks, num_processes)
df_blocks = pd.DataFrame.from_dict(blocks_dict, orient='index')
print(df_blocks)
save_block_data(df_blocks, save_json=True)
transactions_dict = get_all_transactions(cli, blocks_dict, num_processes)
save_transaction_data(transactions_dict, save_json=True)
Output
Starting block data retrieval with 4 parallel processes...
Retrieved block 615330 (10/100) - 10.00% complete
Retrieved block 615320 (20/100) - 20.00% complete
Retrieved block 615310 (30/100) - 30.00% complete
Retrieved block 615301 (40/100) - 40.00% complete
Retrieved block 615291 (50/100) - 50.00% complete
Retrieved block 615280 (60/100) - 60.00% complete
Retrieved block 615269 (70/100) - 70.00% complete
Retrieved block 615260 (80/100) - 80.00% complete
Retrieved block 615250 (90/100) - 90.00% complete
Retrieved block 615240 (100/100) - 100.00% complete
hash ... txidem
615338 d6c227555f3621ae3170ca05f8ba9f3b5293eed0cdf9ac... ... [873ee9a07d8cd59cb81594ac199d7545412d2d2099725...
615337 688207a1379f7ff060dad34f6ce6a05e2ef0a2b97bb10a... ... [17929ec51ffc773f7d208560a876ef9d5d2277acb73dd...
615336 12e99e2488d3427b875c8a6472c931e54645791c3b0b59... ... [6a4e772785f9efcb9b6141c40fcef17d707630a4e0bb7...
615339 b508a7a0b17f328f8b66048a6c7aaaf2e59691be333770... ... [284e6cf7aed9132429b88367201ac853df9ade3ba2613...
615335 9e23de0cbc0d073e005900556ebb5535c72122c8c24ac8... ... [43c9db3cd360ff18d017071a6b793f01c4384d2197419...
... ... ...
615245 78c5b589c6ffa134845349d0046f55f1637871251c81fb... ... [4c248afb8759240f16185ea754feba8c60da7f15acd67...
615242 ec0edb9d6f299706c54c9efa9af9b7091499ebccc8ec6d... ... [62f8b88126968fe7b81612c8d7e273e31852737a6d484...
615241 ad94211a3ee8193d7a561e6fb5fa55b4dc0b06aa184c1b... ... [ebd45e89808f6acd0cf359adefa1ba4d877493ec2b271...
615243 398b94561f9667971f5611417427c87fbd8c0bb715162e... ... [ee099d91cdbc497ee4081e9999b914db6096ffa8f6504...
615240 349a45fdda4ddbe97e5e367687e937e6cdb971b802d71d... ... [0be4bf88a5fb9ecee62014f2287e9ce9c7196960d0e71...
[100 rows x 22 columns]
Block data saved to nexa_last_blocks.json
Starting transaction data retrieval with 4 parallel processes...
Processed transaction (1/176) - 0.57% complete
Processed transaction (11/176) - 6.25% complete
Processed transaction (21/176) - 11.93% complete
Processed transaction (31/176) - 17.61% complete
Processed transaction (41/176) - 23.30% complete
Processed transaction (51/176) - 28.98% complete
Processed transaction (61/176) - 34.66% complete
Processed transaction (71/176) - 40.34% complete
Processed transaction (81/176) - 46.02% complete
Processed transaction (91/176) - 51.70% complete
Processed transaction (101/176) - 57.39% complete
Processed transaction (111/176) - 63.07% complete
Processed transaction (121/176) - 68.75% complete
Processed transaction (131/176) - 74.43% complete
Processed transaction (141/176) - 80.11% complete
Processed transaction (151/176) - 85.80% complete
Processed transaction (161/176) - 91.48% complete
Processed transaction (171/176) - 97.16% complete
Transaction data saved to nexa_transactions.json
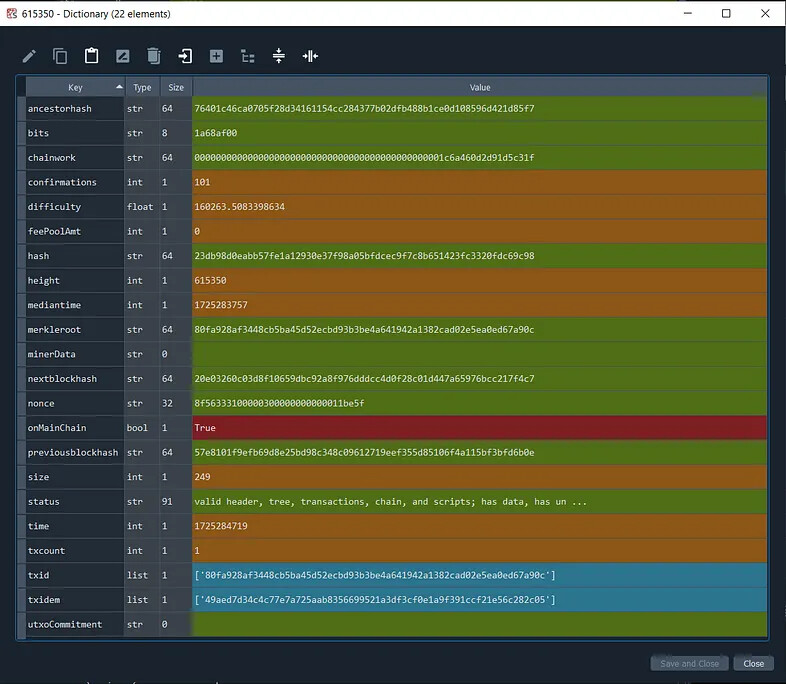
Using Spyder IDE variable explorer, the raw JSON data inside a block is as follows:
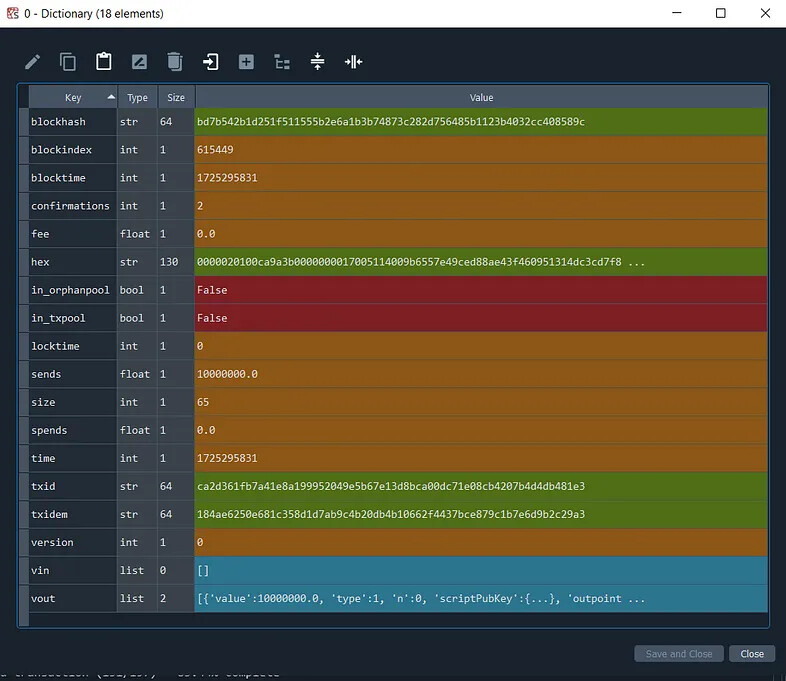
And the raw transaction data for a single transaction looks like this:
Part 3: Read JSON-file, convert data into timeseries, then plot time-series data
In this section, we will utilize the Pandas library in Python to transform raw JSON data, obtained from the nexa-cli, into a time-series format suitable for analysis. This converted data will then be visualized using the Matplotlib library to generate clear and informative graphs.
The script begins by reading block and transaction data from JSON files and converting them into Pandas DataFrames. It then processes this data including calculating hourly transaction volumes, transaction fees, the total number of transactions, and mining difficulty levels. Finally, the processed data points are plotted over time, offering an insightful visual representation of the trends and patterns within the dataset.
Main Execution Flow
The script’s main block performs the following steps:
- Read Block Data:
Reads block data from a JSON file and processes it into a DataFrame. - Process Block Data:
Filters and processes the block data to create a DataFrame with a datetime index. - Calculate Hourly Difficulty:
Computes the difficulty level for each hour. - Read Transaction Data:
Reads transaction data from a JSON file and processes it into a DataFrame. - Process Transaction Data:
Filters and processes the transaction data to create a DataFrame with a datetime index. - Calculate Hourly Volume and Fees:
Aggregates the transaction volume and fees on an hourly basis. - Calculate Transactions per Hour:
Counts the number of transactions per hour. - Plot Time Series Data:
Plots the time series data for hourly volume, fees, transactions, and difficulty.
import json
import pandas as pd
import matplotlib.pyplot as plt
def read_json_file(file_path):
"""
Reads a JSON file and returns its content.
:param file_path: Path to the JSON file.
:return: Data contained in the JSON file.
"""
try:
with open(file_path, 'r') as f:
data = json.load(f)
print(f"Successfully read JSON file: {file_path}")
return data
except Exception as e:
print(f"Error reading {file_path}: {e}")
return None
def process_block_data(block_data):
"""
Processes block data into a DataFrame with a datetime index.
:param block_data: List of block dictionaries.
:return: DataFrame with processed block data.
"""
# Convert block data to DataFrame
df_blocks = pd.DataFrame(block_data)
# Filter the desired columns from df_blocks and make a copy to avoid SettingWithCopyWarning
columns_to_keep_blocks = ['height', 'size', 'txcount', 'time', 'mediantime', 'difficulty']
df_filtered_blocks = df_blocks[columns_to_keep_blocks].copy()
# Convert 'time' column to datetime and set as index for df_filtered_blocks
df_filtered_blocks.loc[:, 'time'] = pd.to_datetime(df_filtered_blocks['time'], unit='s')
df_filtered_blocks.set_index('time', inplace=True)
# Sort df_filtered_blocks in ascending order by the datetime index
df_filtered_blocks.sort_index(ascending=True, inplace=True)
return df_filtered_blocks
def process_transaction_data(transaction_data):
"""
Processes transaction data into a DataFrame with a datetime index.
:param transaction_data: List of transaction dictionaries.
:return: DataFrame with processed transaction data.
"""
# Convert the list of transaction dictionaries into a DataFrame
df_transactions = pd.DataFrame(transaction_data)
# Create a new DataFrame with only the desired columns for transactions and make a copy to avoid SettingWithCopyWarning
columns_to_keep_transactions = ['size', 'locktime', 'spends', 'sends', 'fee', 'blockindex', 'blocktime', 'time', 'confirmations']
df_filtered_transactions = df_transactions[columns_to_keep_transactions].copy()
# Convert 'time' column to datetime and set as index for df_filtered_transactions
df_filtered_transactions.loc[:, 'time'] = pd.to_datetime(df_filtered_transactions['time'], unit='s')
df_filtered_transactions.set_index('time', inplace=True)
# Sort df_filtered_transactions in ascending order by the datetime index
df_filtered_transactions.sort_index(ascending=True, inplace=True)
return df_filtered_transactions
def calculate_hourly_volume_and_fees(df_filtered_transactions):
"""
Calculates hourly volume and fees aggregation based on the 'sends' and 'fee' columns.
:param df_filtered_transactions: DataFrame with transaction data and datetime index.
:return: DataFrame with hourly aggregated volume and fees.
"""
# Ensure 'sends' and 'fee' columns are numeric
df_filtered_transactions['sends'] = pd.to_numeric(df_filtered_transactions['sends'], errors='coerce')
df_filtered_transactions['fee'] = pd.to_numeric(df_filtered_transactions['fee'], errors='coerce')
# Resample the data to hourly frequency and calculate the sum of 'sends' and 'fee' for each hour
df_hourly_aggregation = df_filtered_transactions.resample('H').agg({'sends': 'sum', 'fee': 'sum'})
# Rename columns for clarity
df_hourly_aggregation.rename(columns={'sends': 'hourly_volume', 'fee': 'hourly_fees'}, inplace=True)
return df_hourly_aggregation
def calculate_transactions_per_hour(df_filtered_transactions):
"""
Calculates the number of transactions per hour.
:param df_filtered_transactions: DataFrame with transaction data and datetime index.
:return: DataFrame with the count of transactions per hour.
"""
# Resample the data to hourly frequency and count the number of transactions for each hour
df_transactions_per_hour = df_filtered_transactions.resample('H').size()
# Convert the series to a DataFrame for easier handling
df_transactions_per_hour = df_transactions_per_hour.to_frame(name='transactions_per_hour')
return df_transactions_per_hour
def calculate_hourly_closing_difficulty(df_filtered_blocks):
"""
Calculates the closing difficulty level for each hour.
:param df_filtered_blocks: DataFrame with block data and datetime index.
:return: DataFrame with the closing difficulty level for each hour.
"""
# Resample the data to hourly frequency and get the last difficulty value for each hour
df_hourly_closing_difficulty = df_filtered_blocks['difficulty'].resample('H').last()
# Convert the series to a DataFrame for easier handling
df_hourly_closing_difficulty = df_hourly_closing_difficulty.to_frame(name='closing_difficulty')
return df_hourly_closing_difficulty
def plot_time_series(df_hourly_aggregation, df_transactions_per_hour, df_hourly_closing_difficulty):
"""
Plots the time series data including hourly volume, fees, number of transactions, and difficulty.
:param df_hourly_aggregation: DataFrame with hourly aggregated volume and fees.
:param df_transactions_per_hour: DataFrame with number of transactions per hour.
:param df_hourly_closing_difficulty: DataFrame with closing difficulty level for each hour.
"""
plt.figure(figsize=(15, 10))
# Plot hourly volume and fees
plt.subplot(3, 1, 1)
plt.plot(df_hourly_aggregation.index, df_hourly_aggregation['hourly_volume'], label='Hourly Volume', color='blue')
plt.plot(df_hourly_aggregation.index, df_hourly_aggregation['hourly_fees'], label='Hourly Fees', color='green')
plt.title('Hourly Transaction Volume and Fees')
plt.xlabel('Time')
plt.ylabel('Value')
plt.legend()
plt.grid(True)
# Plot number of transactions per hour
plt.subplot(3, 1, 2)
plt.bar(df_transactions_per_hour.index, df_transactions_per_hour['transactions_per_hour'], width=0.03, color='orange', label='Transactions per Hour')
plt.title('Number of Transactions per Hour')
plt.xlabel('Time')
plt.ylabel('Number of Transactions')
plt.legend()
plt.grid(True)
# Plot hourly closing difficulty
plt.subplot(3, 1, 3)
plt.plot(df_hourly_closing_difficulty.index, df_hourly_closing_difficulty['closing_difficulty'], label='Closing Difficulty', color='red')
plt.title('Hourly Closing Difficulty')
plt.xlabel('Time')
plt.ylabel('Difficulty')
plt.legend()
plt.grid(True)
# Display the plots
plt.tight_layout()
plt.show()
if __name__ == "__main__":
# File paths to the JSON files
block_data_file_path = "nexa_last_blocks.json" # Replace with your actual file path if different
transaction_data_file_path = "nexa_transactions.json" # Example filename; update with your actual timestamped file name
# Read and process block data
block_data = read_json_file(block_data_file_path)
if block_data:
df_filtered_blocks = process_block_data(block_data)
print("\nFiltered Block DataFrame with Datetime Index (Sorted in Ascending Order):")
print(df_filtered_blocks)
# Calculate hourly closing difficulty
df_hourly_closing_difficulty = calculate_hourly_closing_difficulty(df_filtered_blocks)
print("\nHourly Closing Difficulty DataFrame:")
print(df_hourly_closing_difficulty)
# Read and process transaction data
transaction_data = read_json_file(transaction_data_file_path)
if transaction_data:
df_filtered_transactions = process_transaction_data(transaction_data)
print("\nFiltered Transaction DataFrame with Datetime Index (Sorted in Ascending Order):")
print(df_filtered_transactions)
# Calculate hourly volume and fees aggregation
df_hourly_aggregation = calculate_hourly_volume_and_fees(df_filtered_transactions)
print("\nHourly Volume and Fees Aggregation DataFrame:")
print(df_hourly_aggregation)
# Calculate the number of transactions per hour
df_transactions_per_hour = calculate_transactions_per_hour(df_filtered_transactions)
print("\nNumber of Transactions per Hour DataFrame:")
print(df_transactions_per_hour)
# Plot the time series data
plot_time_series(df_hourly_aggregation, df_transactions_per_hour, df_hourly_closing_difficulty)
Timeseries data output
Timeseries data created with pandas.
Successfully read JSON file: nexa_last_blocks.json
Filtered Block DataFrame with Datetime Index (Sorted in Ascending Order):
height size txcount mediantime difficulty
time
2024-09-01 06:13:06 614347 267 1 1725170806 155893.386085
2024-09-01 06:14:44 614348 249 1 1725170877 155965.565502
2024-09-01 06:15:04 614349 501 2 1725171023 155981.142375
2024-09-01 06:15:19 614350 249 1 1725171058 156043.480994
2024-09-01 06:15:52 614351 481 2 1725171182 156110.125036
... ... ... ... ...
2024-09-02 13:18:41 615342 249 1 1725282669 160714.785911
2024-09-02 13:19:06 615343 262 1 1725282834 160713.282443
2024-09-02 13:27:03 615344 1530 5 1725282874 160774.947733
2024-09-02 13:29:17 615345 249 1 1725282953 160543.571475
2024-09-02 13:33:49 615346 249 1 1725282997 160534.570294
[1000 rows x 5 columns]
Hourly Closing Difficulty DataFrame:
closing_difficulty
time
2024-09-01 06:00:00 156111.543613
2024-09-01 07:00:00 157371.407215
2024-09-01 08:00:00 158501.006015
2024-09-01 09:00:00 158621.009362
2024-09-01 10:00:00 158344.689064
2024-09-01 11:00:00 157679.063817
2024-09-01 12:00:00 158276.123897
2024-09-01 13:00:00 158417.695975
2024-09-01 14:00:00 158241.134794
2024-09-01 15:00:00 158201.790539
2024-09-01 16:00:00 158246.965236
2024-09-01 17:00:00 158528.795504
2024-09-01 18:00:00 158704.533437
2024-09-01 19:00:00 158147.906103
2024-09-01 20:00:00 158601.972322
2024-09-01 21:00:00 159020.373586
2024-09-01 22:00:00 159180.977901
2024-09-01 23:00:00 158992.411502
2024-09-02 00:00:00 158946.810259
2024-09-02 01:00:00 159039.511206
2024-09-02 02:00:00 159213.432805
2024-09-02 03:00:00 158181.397516
2024-09-02 04:00:00 158197.420163
2024-09-02 05:00:00 157958.873115
2024-09-02 06:00:00 158105.698009
2024-09-02 07:00:00 158455.686180
2024-09-02 08:00:00 159074.854302
2024-09-02 09:00:00 159746.399487
2024-09-02 10:00:00 160070.878546
2024-09-02 11:00:00 160566.078846
2024-09-02 12:00:00 160833.648892
2024-09-02 13:00:00 160534.570294
Successfully read JSON file: nexa_transactions.json
Filtered Transaction DataFrame with Datetime Index (Sorted in Ascending Order):
size locktime ... blocktime confirmations
time ...
2024-09-01 06:13:06 83 0 ... 1725171186 1004
2024-09-01 06:14:44 65 0 ... 1725171284 1003
2024-09-01 06:15:04 65 0 ... 1725171304 1002
2024-09-01 06:15:04 252 614347 ... 1725171304 1002
2024-09-01 06:15:19 65 0 ... 1725171319 1001
... ... ... ... ...
2024-09-02 13:27:03 65 0 ... 1725283623 4
2024-09-02 13:27:03 219 615343 ... 1725283623 4
2024-09-02 13:27:03 657 0 ... 1725283623 4
2024-09-02 13:29:17 65 0 ... 1725283757 3
2024-09-02 13:33:49 65 0 ... 1725284029 2
[2304 rows x 8 columns]
Hourly Volume and Fees Aggregation DataFrame:
hourly_volume hourly_fees
time
2024-09-01 06:00:00 5.656903e+08 760.33
2024-09-01 07:00:00 2.132917e+09 2621.05
2024-09-01 08:00:00 9.093309e+09 1260.43
2024-09-01 09:00:00 2.606980e+09 1383.96
2024-09-01 10:00:00 2.482355e+09 988.27
2024-09-01 11:00:00 8.304505e+08 1099.23
2024-09-01 12:00:00 7.510856e+09 4715.12
2024-09-01 13:00:00 1.178797e+09 1460.56
2024-09-01 14:00:00 1.653545e+09 649.82
2024-09-01 15:00:00 9.647802e+08 3224.35
2024-09-01 16:00:00 2.225825e+10 997.26
2024-09-01 17:00:00 9.483229e+08 1836.24
2024-09-01 18:00:00 1.086877e+09 1571.44
2024-09-01 19:00:00 2.862068e+09 1738.47
2024-09-01 20:00:00 5.662007e+08 421.11
2024-09-01 21:00:00 8.540992e+08 966.35
2024-09-01 22:00:00 7.388806e+08 590.10
2024-09-01 23:00:00 4.041986e+08 384.85
2024-09-02 00:00:00 9.828177e+09 1019.81
2024-09-02 01:00:00 1.152729e+09 2248.23
2024-09-02 02:00:00 9.610255e+09 819.05
2024-09-02 03:00:00 5.452157e+08 660.07
2024-09-02 04:00:00 3.859853e+09 682.21
2024-09-02 05:00:00 4.388962e+09 1498.17
2024-09-02 06:00:00 4.185528e+09 1089.87
2024-09-02 07:00:00 3.952307e+09 1389.04
2024-09-02 08:00:00 7.570182e+09 774.26
2024-09-02 09:00:00 3.740837e+09 1437.63
2024-09-02 10:00:00 3.450036e+09 719.51
2024-09-02 11:00:00 1.658008e+09 4350.02
2024-09-02 12:00:00 1.665032e+09 1323.76
2024-09-02 13:00:00 1.058379e+09 320.84
Number of Transactions per Hour DataFrame:
transactions_per_hour
time
2024-09-01 06:00:00 77
2024-09-01 07:00:00 105
2024-09-01 08:00:00 100
2024-09-01 09:00:00 91
2024-09-01 10:00:00 85
2024-09-01 11:00:00 84
2024-09-01 12:00:00 117
2024-09-01 13:00:00 94
2024-09-01 14:00:00 74
2024-09-01 15:00:00 113
2024-09-01 16:00:00 73
2024-09-01 17:00:00 99
2024-09-01 18:00:00 73
2024-09-01 19:00:00 65
2024-09-01 20:00:00 55
2024-09-01 21:00:00 55
2024-09-01 22:00:00 62
2024-09-01 23:00:00 41
2024-09-02 00:00:00 69
2024-09-02 01:00:00 73
2024-09-02 02:00:00 78
2024-09-02 03:00:00 39
2024-09-02 04:00:00 38
2024-09-02 05:00:00 55
2024-09-02 06:00:00 63
2024-09-02 07:00:00 56
2024-09-02 08:00:00 86
2024-09-02 09:00:00 74
2024-09-02 10:00:00 58
2024-09-02 11:00:00 61
2024-09-02 12:00:00 62
2024-09-02 13:00:00 29
Plot
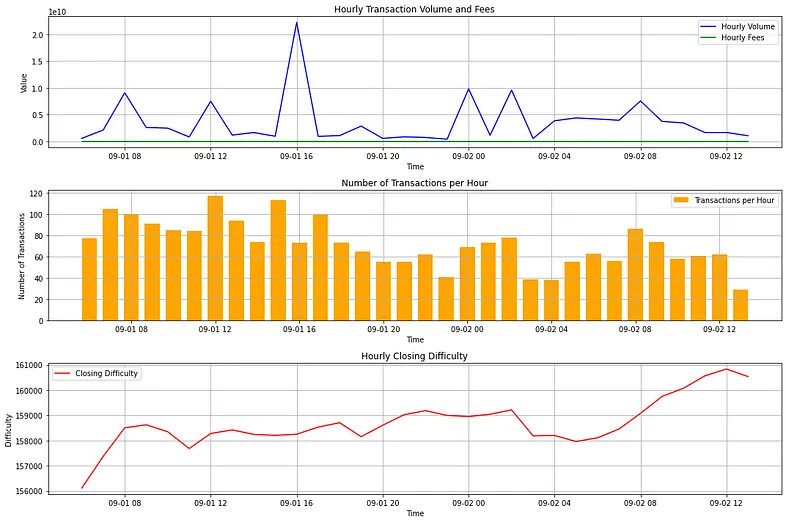
Finally, we use the timeseries data to plot graphs using matplotlib.
Hourly transaction volume, transaction fees and number of transactions per hour is an aggregate of volume, fees and number of transaction within an hour. For example if the hour of the datetime index is 18:00, it aggregates the values between 18:00 and 19:00.
And the difficulty is a ‘levels’ variable, where the ‘closing’ means that it uses the difficulty value from the latest block within that hour interval. The timeseries interval can easily be changed to another time-interval by changing the input of the resample('H') function. See documentation.
Thoughts on Efficiency
There is potential to enhance the efficiency of the data retrieval process when accessing Nexa blockchain data. Optimizing the way data is requested and retrieved could significantly reduce processing time and resource consumption, achieving more streamlined and scalable on-chain data retrieval. To make the retrieval process more efficient, consider the following optimizations:
- Persistent Connection: Instead of opening a new command line instance for each query, maintain a persistent connection to the command line or use a more efficient method, such as direct RPC (Remote Procedure Call) communication with the Nexa daemon. This would avoid the overhead of repeatedly starting and stopping the command line process.
- Batch Requests: Modify the script to batch multiple requests into a single command where possible. For instance, retrieve multiple blocks or transactions in one go, reducing the number of individual
subprocess.runcalls.
Thanks for reading until the end! Please clap for the article or reply with feedback and improvement suggestions.
(Originally posted on Medium: Nexa Blockchain Timeseries Visualization using Python on Windows | by Aksel Jansen | Sep, 2024 | Medium)
Find the full code in GitHub HERE