
A video and transcript of the talk Peter Rizun gave at the Australian Cryptocurrency Convention in Sydney on November 23, 2024.
The Power and Potential of Custom Hardware
This afternoon we are going to explore building a microchip for cryptocurrency. A microchip that can do the same thing as a software node but is faster, more reliable, uses less energy, and can be built for a fraction of the cost.

This “hardware approach" paid dividends for bitcoin mining. Satoshi mined the first bitcoin with his CPU on Jan 3, 2009. Shortly afterwards, people realized they could mine faster and earn more profit by programming a GPU to do the mining instead. Later still, innovative people figured out how to make an electrical circuit for mining and etched that circuit onto a tiny silicon die: the era of the ASIC miner was born. Every year since, mining companies release new, faster, lower power, and cheaper mining rigs, which then compete to find the next block.
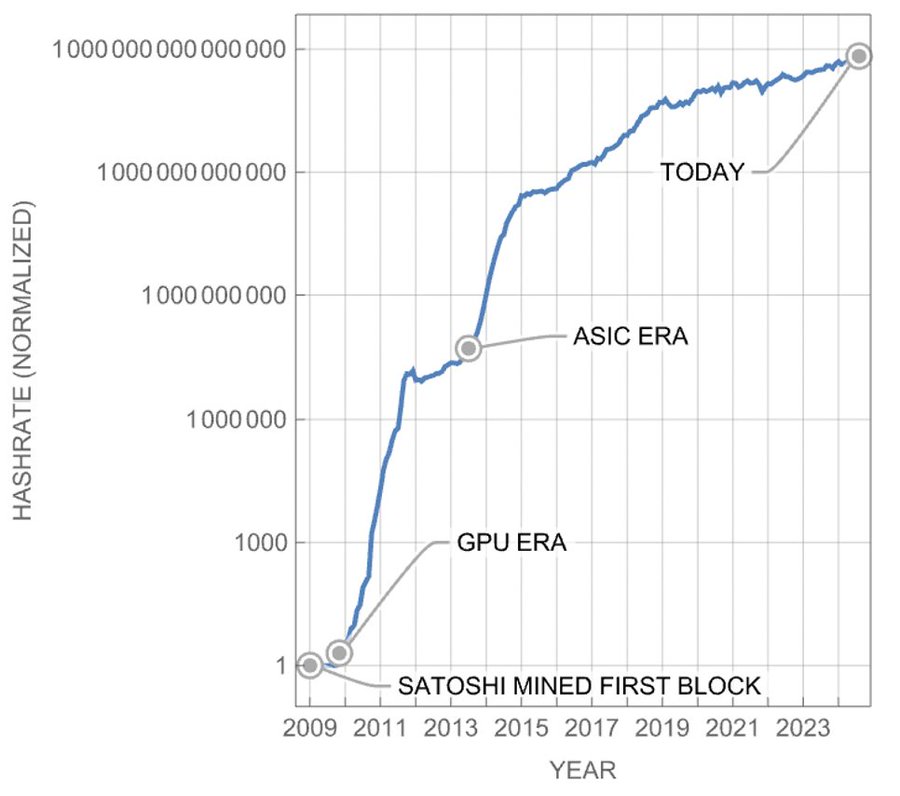
Fig. 1. Bitcoin network hashrate over the CPU-, GPU- and ASIC-eras.
The efficiency of the technology has increased tremendously too. Satoshi’s Intel i7 could perform about 100,000 hashes for every joule of electrical energy it consumed. The first GPU miners could do about 1.2 million hashes per joule. The earliest ASIC miners about 500 million hashes, and the best miners today (2024) can do about 60 billion hashes for that same joule of energy. So there has been a 600,000X improvement in the technology since 2009 (1,2).
But the graph of network capacity in transactions per second has remained flat. It’s about 7 tx/sec today, it was 7 tx/sec a decade ago, and it was 7 tx/sec in the days of Satoshi. But if transactions per second had increased proportionately with the progress in mining chips, the Bitcoin network would be able to process 4.2 million transactions per second today!
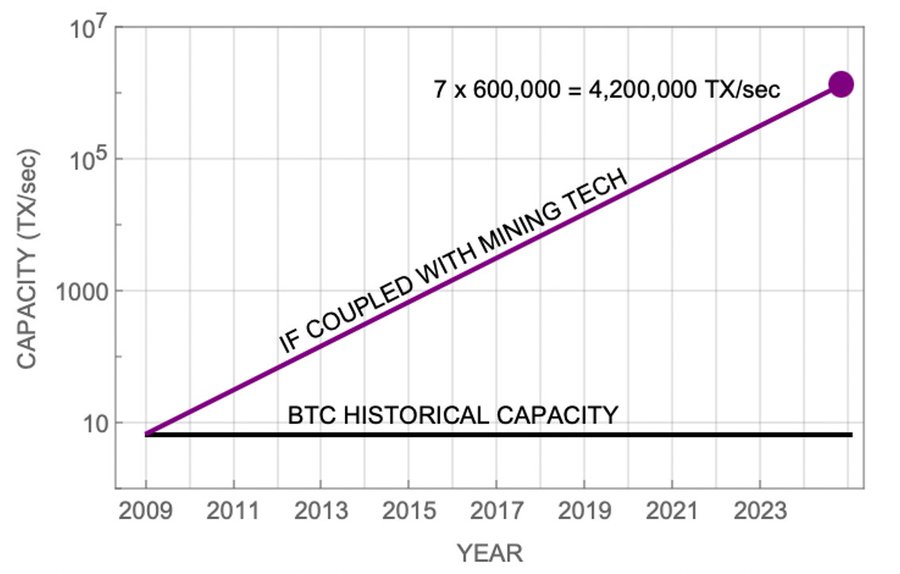
Fig. 2. Historical transactional capacity compared to the transaction capacity if it were coupled with the 600,000X improvement in mining technology.
Why aren’t miners supporting the network? Why aren’t they building these amazingly-fast full nodes that could keep up with global-scale transaction throughput? It’s obvious to me that Satoshi wanted them to:
“This [newly mined coins] adds an incentive for nodes to support the network” – Satoshi Nakamoto, Bitcoin white paper, 2008
I think the answer to why this didn’t happen is nuanced. I think proof-of-work was the right idea, but Satoshi picked the wrong hash function. Rather than sha256, he should have picked a hash function such that a miner’s hash rate was equal to the rate at which that miner could validate transactions. If he had done so, the massive improvements we’ve seen in mining technology would have been coupled to equally-impressive improvements in bitcoin full-node technology.
This brings me to my role at Nexa. While Andrew Stone leads a “top down” effort building off of the Satoshi code base, I lead a “bottom up” effort implementing what Satoshi described in the white paper directly in hardware. I’m not writing any software or even using a CPU: instead, I’m building a node as a circuit of digital logic gates. Our hope is that when these two approaches converge, that we have achieved our goal of building a better bitcoin.
A Quick Review of Digital Logic
To continue with this talk, we need to do a quick review of the building blocks of digital logic. The most important component is shown in the first row of Fig. 3: it’s a wire. Its behavior is so simple that it is beyond the grasp of many software developers. If I apply 0 volts to the input, I get 0 at the output. If I apply 1 volt at the input, I get 1 at the output. You can model this in Python as shown: it’s a while loop that is always mapping the input to the output. In Python, it takes hundreds of clock cycles for the input signal to propagate to the output. How long does it take in the hardware case? This is the question that stumps the software guys. They might answer that with a lot of work it could be as fast as 1 clock cycle. But that’s totally wrong! It takes no work at all and the signal propagates at the speed of light. It is literally just a wire. This is part of why hardware can be so fast: you get this built-in “while loop” for free.
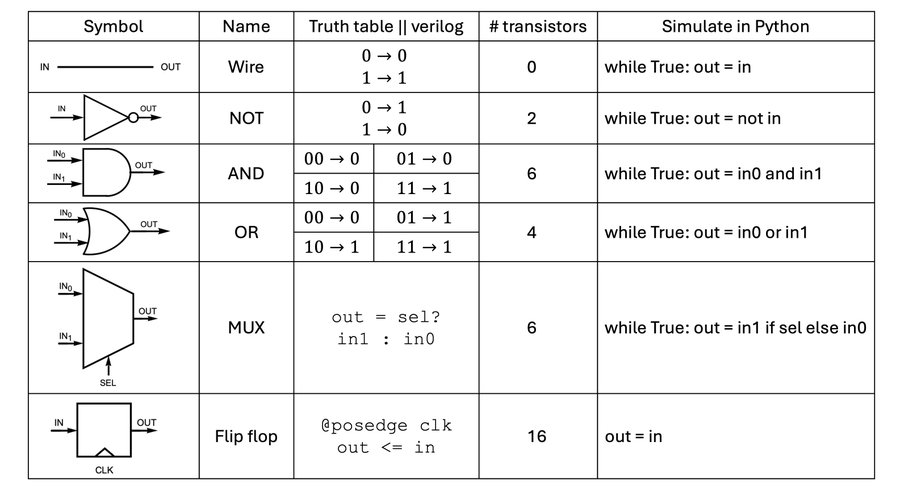
Fig. 3. Building blocks of digital logic.
Below the wire we have a NOT gate: if the input is 0 the output is 1 and vice versa. Next is an AND gate: its output is 1 only if all of its inputs are 1. An OR gate’s output is 1 if any of its inputs are 1. A multiplexer is like a switch: the select line picks which of the two inputs gets routed to the output. The final gate is a flip-flop and is used to create memory. On the rising edge of the clock signal, the input is saved to the flip-flop’s output.
Together, these gates form a Turing-complete set [see NOTE 2]. Any computation that can be performed, can be performed by a suitable circuit made of combinations of these six components. Another way to look at it is that you could solder together your own Turing machine using only these six building blocks.
Bits versus symbols—a wire carries a single bit; a flip-flop stores a single bit. A bus is a collection of wires and carries a bunch of bits that we call a “symbol.” Symbols are saved in registers. Registers are just a bunch of flip-flops side-by-side.
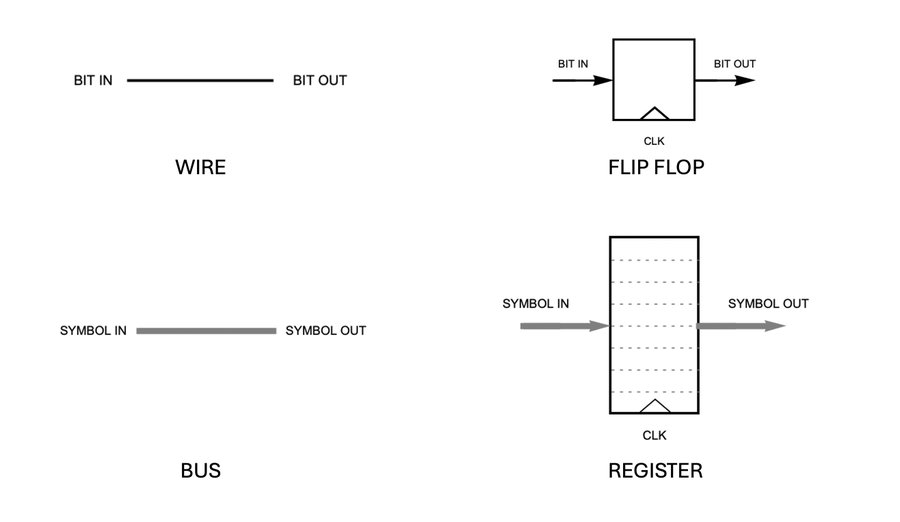
Fig. 4. Wires carry bits and flip-flops store bits. Buses carry symbols and registers store symbols. A bus is an array of wires; a register is an array of flip-flops with a shared clock input.
Implementing a Better Bitcoin Node in Hardware
Now let’s get started building our hardware node. We start with an abstract description of our validation engine (Fig. 5). It consists of a tape of squares, and on each square a symbol may be written. The read/write head can inspect the symbol on the square in front of it, and optionally can overwrite it. It can also splice a new square into the tape or remove a square from the tape. Lastly, it can request information from the UTXO database. And that’s basically it. That’s our validation engine!
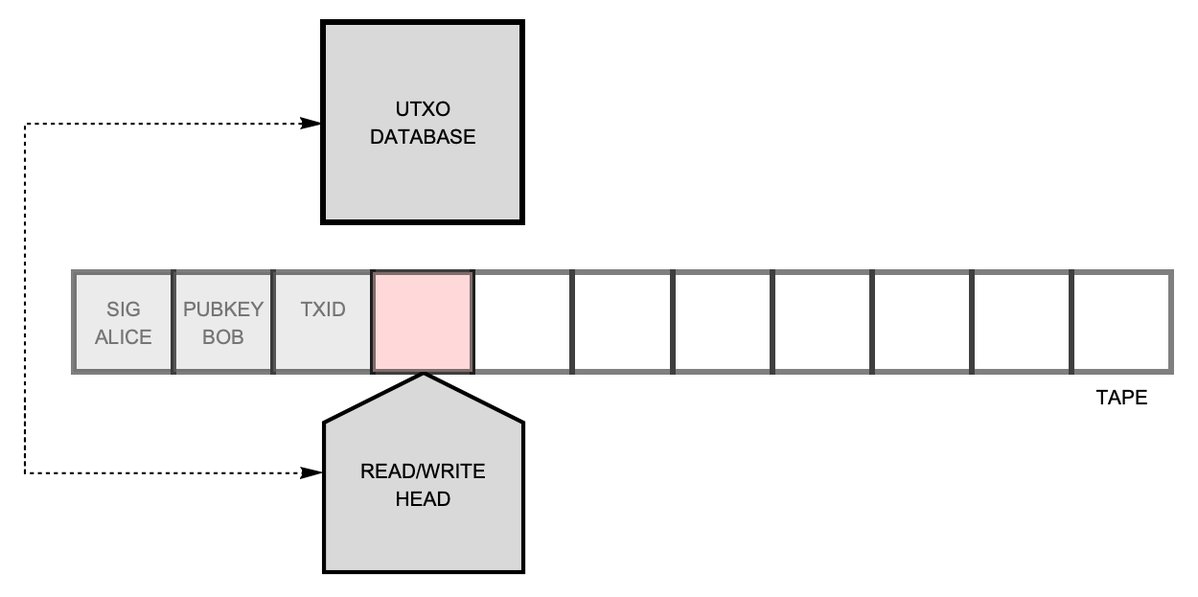
Fig. 5. Abstract description of a bitcoin transaction-validation engine.
With that out of the way, what are our goals for our hardware node? What properties do we want our better bitcoin to have?
My answer is that we want it to be
- Scalable,
- Compressible,
- Extensible, and
- Incentive-compatible.
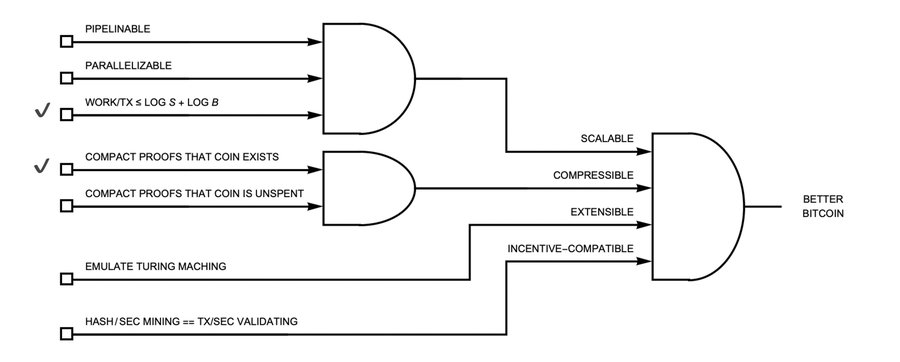
Fig. 6. Desired properties of the “better bitcoin” hardware node.
By scalable, I mean that it must be (a) pipelinable, (b) parallelizable, and (c) that the work to validate a transaction most grow very slowly with the network size. The system is pipelinable if we can validate transactions with the tape only moving in the forward direction. It is parallelizable if we can have more than one validation engine running in parallel. Lastly, by “grow very slowly with the network size” I mean the per-transaction work must scale no worse than the logarithm of the global state size and the logarithm of the block size.
By compressible I mean two things: (1) we need a way to show that a coin exists with a small compact proof. And (2) we need a way to show that a coin is unspent with a separate compact proof. By compact I mean that the size of the proof must grow no faster than the logarithm of the block size or the logarithm of the global state size, respectively. Bitcoin already has the first: it’s the Merkle-branch proofs in the SPV section of the white paper, but it doesn’t have the second.
By extensible, I mean that our validation engine can emulate a Turing machine. If it can emulate a Turing machine, then it can be extended to perform any possible script with a suitable extension to just the circuit inside the read/write head (a highly-localized change).
And I’ve already talked at length about how I want the hash/sec mining to be coupled to tx/sec validating—which is what I mean when I say incentive-compatible.
It turns out that it only takes three changes to Satoshi’s bitcoin to check all of the boxes in my wish list:
- Calculate the root hash for a block using a compact bitwise prefix tree rather than a Merkle tree [see NOTE 3]. This builds on Amaury Sechet’s idea to hash the block as a set rather than as a list. This change makes it scalable. Strangely, it also turns our validation engine into a Turing machine and thus makes it extensible.
- Store the UTXO set in a compact bitwise prefix trie and commit to the tree’s root hash in the block header. This builds on ideas from the “Ultimate Blockchain Compression” thread on
Bitcointalk.org
from 2012. This change makes it compressible. It makes it possible to prove that a coin is unspent with a compact proof. - Use a hash function that forces the miner to exercise the entire transaction validation pipeline. This change makes it incentive-compatible. It makes a node’s transaction-validation capacity scale with its hash rate.
Now let’s zoom in to the wire-and-gate level. I implemented the tape using a bunch of wires—a bus—and I connected those wires to the head so it can read and write the symbols. There is also a wire, for every type of symbol, that lets the head know how to interpret the symbol it sees: is it a pubkey? Is it a signature? Is it something else?
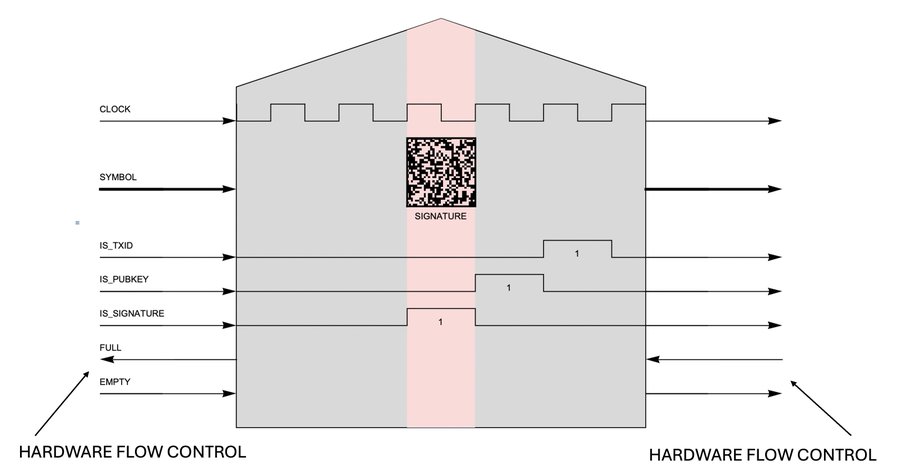
Fig. 7. Electrical connections to the read/write head. The “tape” is implemented as a bus: the next symbol passes in front of the head on the rising edge of each clock cycle. The head can pass the symbol to the output unchanged, or it can modify the symbol.
The clock rate I’ve been using is 100 MHz, which means that 100 million symbols are flying past the head each second. But sometimes the head needs longer than 10 ns to perform its operation on the square in front of it. For example, it takes about 20 us in hardware to verify a digital signature. For this reason, I needed to add the “FULL” and “EMPTY” wires shown in Fig. 6. These wires implement hardware flow control. To get more time, the head asserts the “full” wire, which tells the upstream circuit not to send any more symbols. This flow-control signal propagates in a few dozen picoseconds (less than the clock period) so the bus stops instantly. When the head is done verifying the signature, it can release the flow-control lines to restart the flow of symbols. It is not possible to achieve sub-nanosecond flow control like this in software.
Pipelinability
Now let’s get our validation engine to process a transaction. Here is the diagram from Satoshi’s white paper that explains how it works.
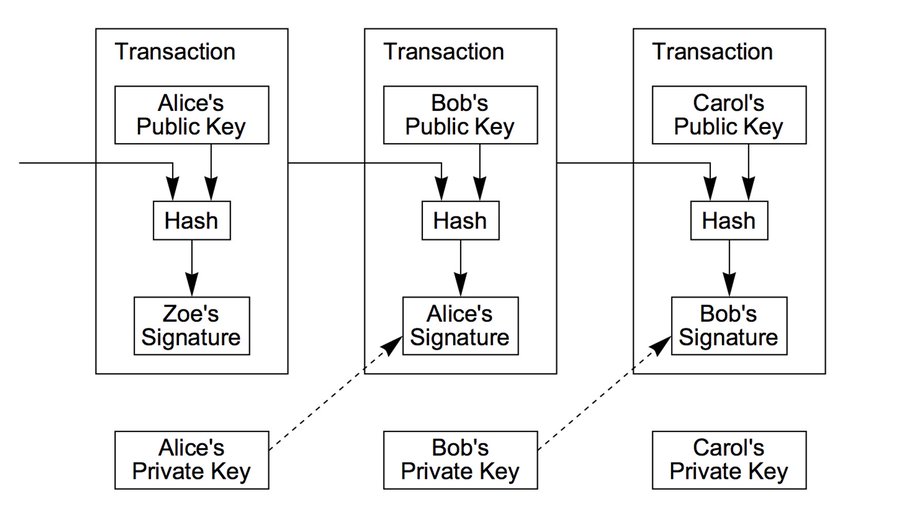
Fig. 8. Diagram from the Bitcoin white paper illustrating how an electronic coin is a chain of digital signatures.
Alice’s transaction that pays Bob contains:
{TXID, PUBKEY-BOB, SIGNATURE-ALICE}
But in order to validate this transaction, our node needs to know Alice’s pubkey and this thing called a signing hash:
{TXID, PUBKEY-ALICE, PUBKEY-BOB, SIGNING HASH, SIGNATURE-ALICE}
The node gets the pubkey from its UTXO set, and it calculates the signing hash directly. Here is an animation showing how this works in hardware:
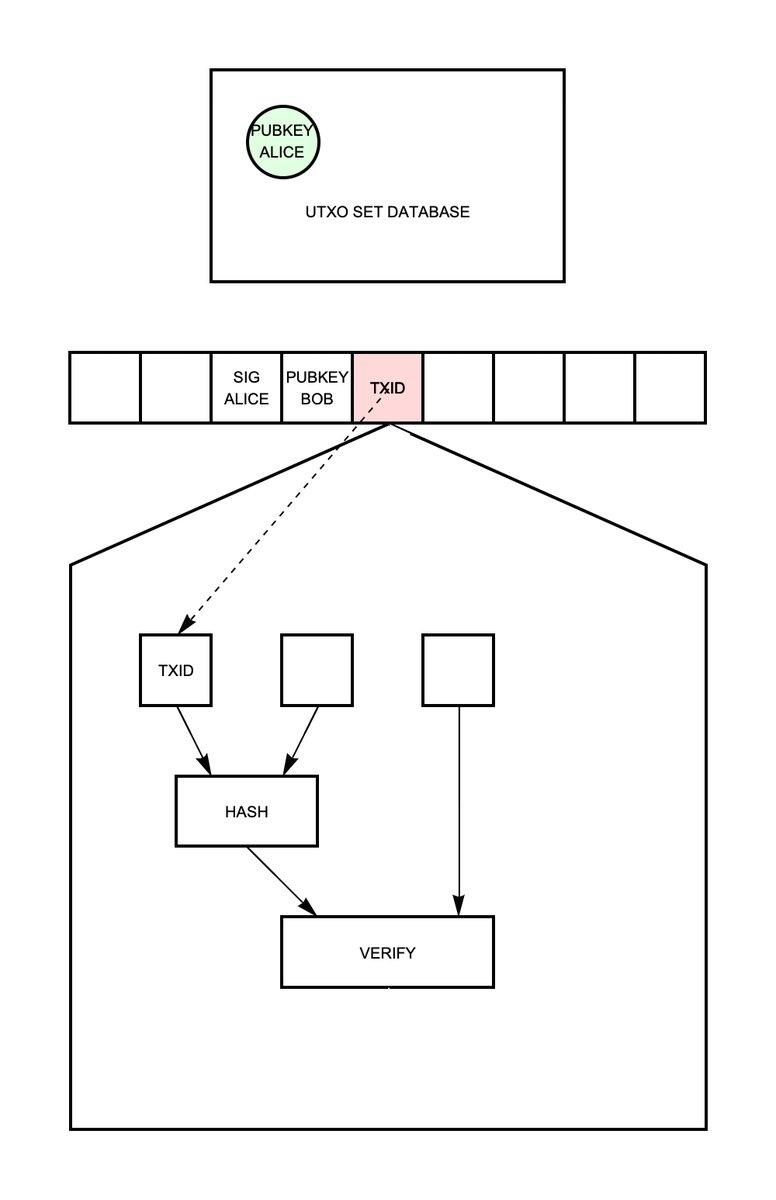
Fig. 9. Animation of the transaction-verification process in hardware.
First the head sees the ID of the coin being spent. It saves a copy of this symbol into an internal register, and it looks up the coin from its UTXO database. If the coin exists and is unspent, then Alice’s pubkey can be retrieved. The head saves this pubkey to a second internal register and it also splices her pubkey into the tape. The next symbol passes by, which is Bob’s pubkey, which gets saved into a third internal register. Now there is enough information to compute the signing hash. This circuit automatically calculates it (no intervention is required because it’s just fixed hardware operating autonomously), and splices a copy of the signing hash into the tape. The next symbol passes in front of the head, which is Alice’s signature, and now we have all the information needed to verify the transaction. The hardwired “verify” module runs autonomously and if the signature is valid the head writes “valid” into the signature symbol and adds what is now Bob’s coin to the UTXO set. And we’re done!
I’ve demonstrated that transactions can be validated with the tape moving only in the forward direction, which means I get to check the pipelinable box in my wish list.
Parallelizability
Let’s look into parallelizability next. In Fig. 10, I’ve added a second validation pipeline in parallel to the first. There is a switch which routes transactions to whichever pipeline is not busy. The first problem we encounter is that both heads must access the same UTXO set. If Pipeline 1 spends a coin, that coin must be spent from the perspective of Pipeline 2 as well. But what if both pipelines attempt to spend the same coin on the same clock cycle? This is a race condition that we must prevent.
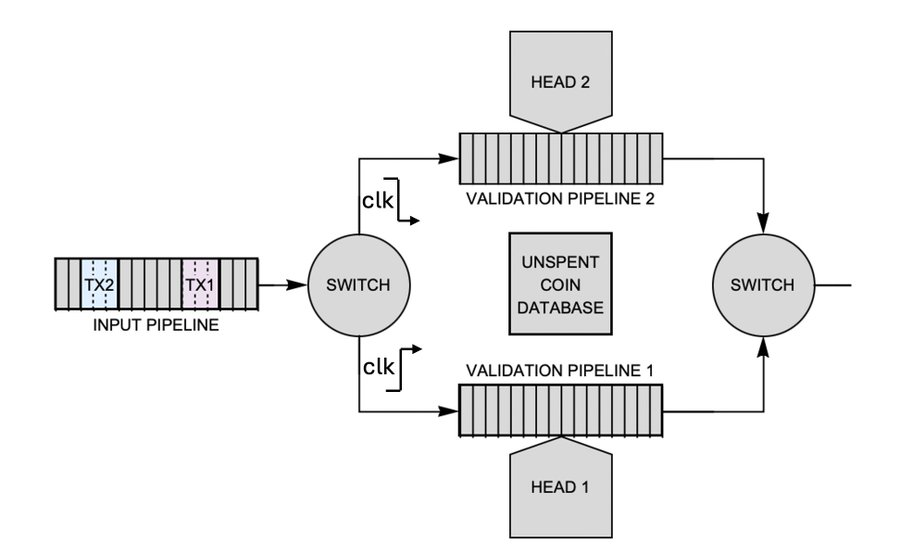
Fig. 10. Two validation engines running in parallel.
It’s really easy to prevent this race condition in hardware. What we do is invert the clock signal to Pipeline 2 so that it is physically impossible for the two heads to access the same coin at the same time. Either Pipeline 1 grabs the coin on the clock’s rising edge, or Pipeline 2 grabs the coin on the clock’s falling edge.
The other problem we encounter is that the transactions might come out in a different order than they went in. For example, TX2 might come out and enter our block candidate before TX1.
If our node solves the block, its peer might reassemble the block in a different order, calculate a different root hash, and thus reject the block as invalid. This can be fixed by sorting the block, but sorting is not pipelinable as the tape needs to move forwards and backwards. So we don’t want to sort because sorting doesn’t scale. If we interpret the white paper literally, Bitcoin is either parallelizable or it is pipelinable, but it cannot be both.
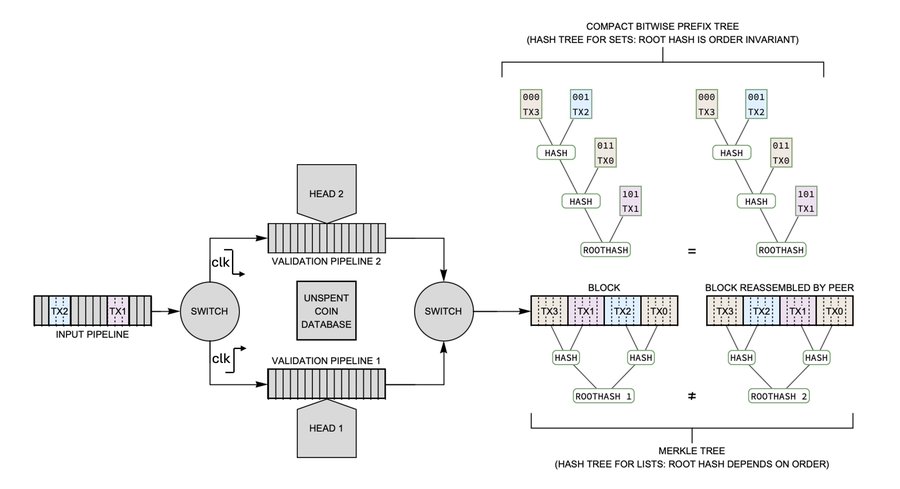
Fig. 11. The root hash of a Merkle tree depends on the order of the transactions; the root hash of a compact bitwise prefix trie depends on only the set of transactions.
Now, I don’t think Satoshi literally meant a Merkle tree. I think he meant a binary tree that would work for SPV proofs. The problem is that a Merkle tree is for lists; what Satoshi really wanted was a tree for sets. A tree with this property is the compact bitwise prefix tree [see NOTE 3]. It still works for SPV proofs but it also produces the same root hash regardless of the order of the transactions in the block. As long as the two sets of transactions are equal, the root hashes will also be equal. If we use this new tree we can eliminate the need for sorting and recover the pipelinable property. I now get to check the parallelizable box, which flips the first AND gate in Fig. 6 to True and thus our coin is now scalable.
So why are pipelinability and parallelizability such a big deal? The answer is that with pipelinability we can guarantee that our throughput can be as fast as the reciprocal of the slowest step in the pipeline (e.g., signature verification). The pipeline depth can be increased until the other shorter latencies no longer matter. With parallelizability, the system throughput gets multiplied by the number of parallel validation engines. This is thus a system that scales to nearly [see NOTE 1] any level just by increasing the pipeline depth and the number of parallel validation engines.
Extensibility
I mentioned earlier how this change strangely also gave us a Turing machine. Let’s dig in deeper to see how. Consider the case where Alice pays Bob and then Bob immediately pays that coin to Carol. Remember, we can’t control the order in which the transactions are processed. This means that the payment from Bob to Carol might get checked before the payment from Alice to Bob. When Head 1 looks up Bob’s coin from the UTXO set, it doesn’t find it. But nor does it find proof that the coin was already spent. So this transaction cannot be marked as valid, but it cannot be marked as invalid either. It is undecided!
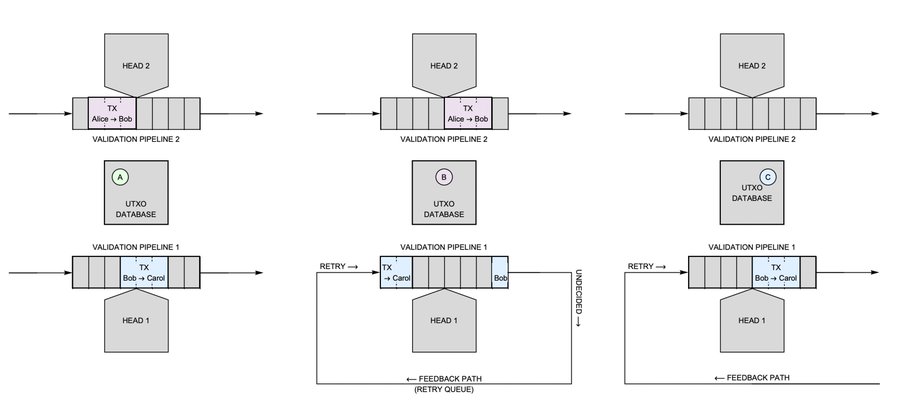
Fig. 12. Adding a feedback path back to the input allows some undecided transactions to be resolved.
To deal with undecided transactions, we must add a 3rd pipe that feeds those transaction back into the input. When this transaction re-enters Pipeline 1, Bob’s coin is sitting in the UTXO set and the transaction can be validated. It is the fact that a transaction can remain “undecided” that makes the feedback path necessary. And it is the feedback path that allows this machine to emulate a Turing machine. This is easy to see:
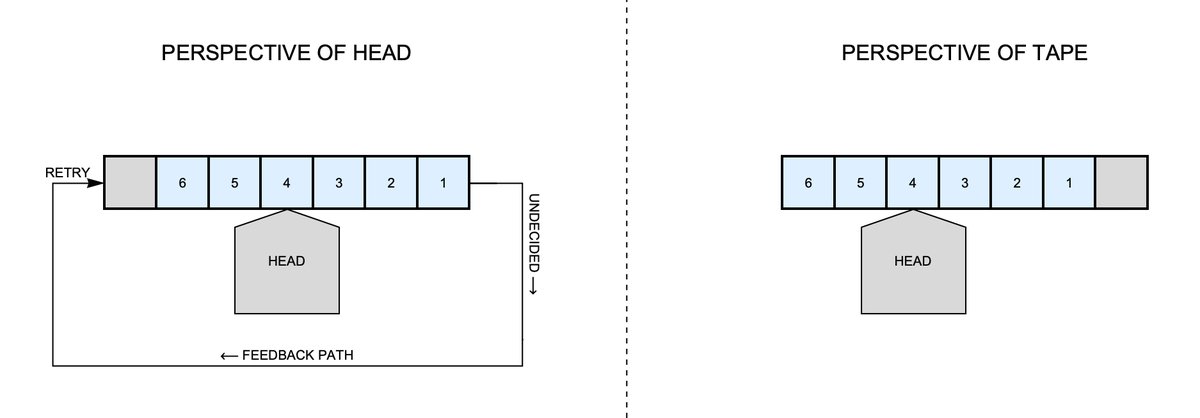
Fig. 13. Because of the feedback path, the head can process the same section of “tape” multiple times.
From the perspective of the head, the tape is doing loops in front of it. From the perspective of the tape, the head is walking to the end, and then starting over at the beginning.
But remember that the head controls the flow control lines so it can stop the tape at any square it wants. And so it can really look like this:

Fig. 14. The head can stop the tape on any square because it controls the flow control wires. Thus thus head can move both right and left across the tape.
That is, the head can move both right and left on the tape. We already showed how the head could insert new squares into the tape, so the length of the tape is unbounded. And, as many of you know, this is all we need to show that our validation engine can emulate a Turing machine.
I’d need another 25 min slot to talk about all the amazing possibilities this opens up. But I’ll say that with this architecture we can add things like quantum-resistant signature schemes, purely in script, without even requiring a hard or soft fork. So we can now tick the extensible box in our wish list.
Compressibility
The next step is to make our cryptocurrency compressible. Currently, full validating nodes use their UTXO set to determine whether a coin exists and is unspent. But they could get that “unspent status” from a compact proof, if such a proof were possible.
We can easily make it possible! Miners would store the UTXO set in a compact bitwise prefix trie and include the trie’s root hash in the block header (right beside the root hash for the block).
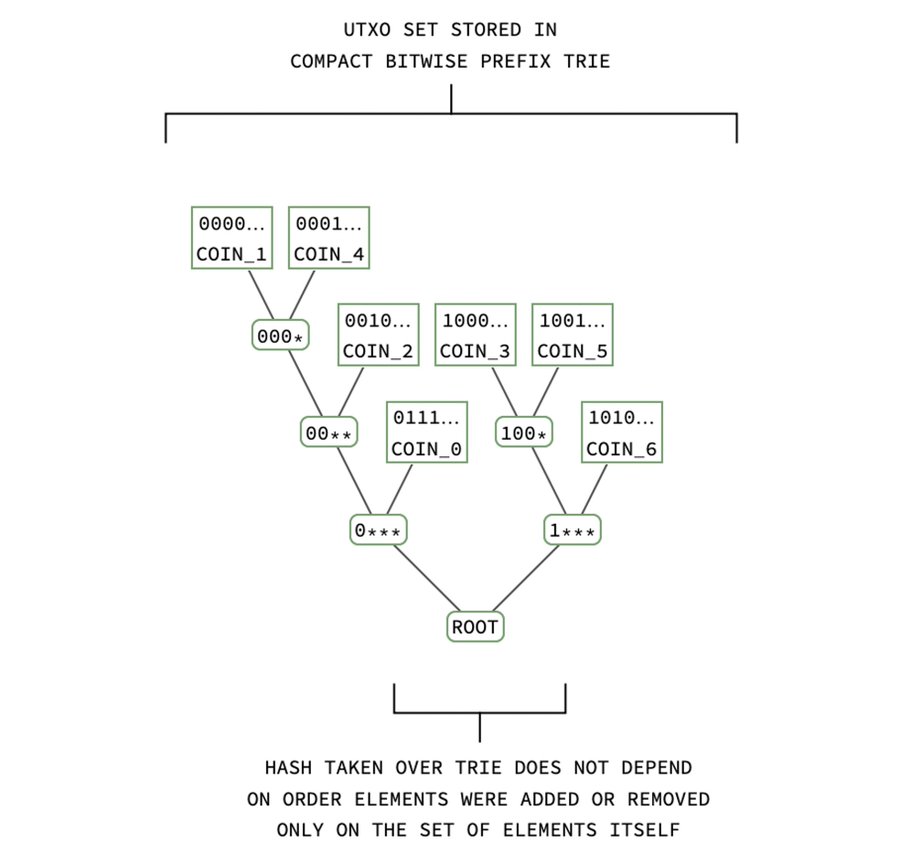
Fig. 15. Storing the UTXO set in a compact bitwise prefix trie and including the trie’s root hash in the block header enables compact proofs that a coin is unspent.
Full nodes can now check that a coin is unspent with only a branch proof to the block header. There is no longer a need for full validating nodes to maintain a UTXO database.
Calculating the UTXO root hash is not hard for the miners. It is pipelinable, parallelizable, and has O(log S) complexity per insertion/deletion (where S is the state size), and so it meets our definition for scalable.
I’ve now shown how we can add compact proofs that a coin is unspent, which means I get to tick the fifth box in Fig. 6, which makes our coin compressible.
Incentive-Compatibility
Now we just need to make our coin incentive-compatible. This is hard because we need to make our own ASIC.

Fig. 16. 3-D rendering of the Nexa-PoW ASIC.
This is a 3D rendering of the Nexa-PoW ASIC. It is just a 10mm x 10mm ball grid array that looks like any other microchip. But inside it is a bitcoin full-node-core that can process 1 million transactions per second. It also supports NEXA’s extended instruction set, to do the useful things with Script that Andrew Stone discussed. It has 32 parallel transaction validation engines, 32 elliptic curve point multipliers for fast signature verification, integrated mining cores, and a massively parallelized tree-root-hashing circuit. In total, it’s about 360 million transistors, which seems like a lot, but some GPUs now have 100 billion transistors so this is actually not a large chip. TSMC is the big semiconductor fab in Taiwan and their 16 nm process can place about 40 million transistors per square millimeter of silicon. So the die inside this chip will be a 3mm square. Something that could easily fit on the tip of your finger, or maybe even be balanced on the head of a pin.
The Nexa-PoW algorithm, which is implemented inside this chip, involves verifying a digital signature AND updating the UTXO set, which are the two bottlenecks of full node scaling. To mine, the chip uses the exact same hardware pipeline as it does to validate, so mining and transaction validation truly are 1:1.
- nonce ← nonce+1
- coinbase ← {nonce, input1, … , inputN}
- insert new coinbase into UTXO set
- utxohash ← treehash(current UTXO set)
- x ← sha256(prevblock||nonce||roothash||utxohash)
- y ← sqrt(x^3 + 7)
- r ← hash(x)
- s ← hash(y)
- e ← hash(r||x||y)
- P ← {x, y}
- R ← s⋅G + e⋅P // G is base point
- testhash ← hash(R)
PoW succeeds if testhash ≤ target (fail if any step fails)
When the chip is ready we’ll get to tick the last box here and achieve my vision for a better bitcoin.
The chip won’t be ready until 2026 at the earliest. But there is a lot of useful things we can do directly in hardware in the meantime…
Node by Nexa
This is node by Nexa. It is a small hardware-accelerated cryptocurrency full node. It has a network connector, a removable memory card for storing the blockchain, a switch to toggle between mainnet and testnet, and a USB port for debugging and loading new FPGA bitstreams.
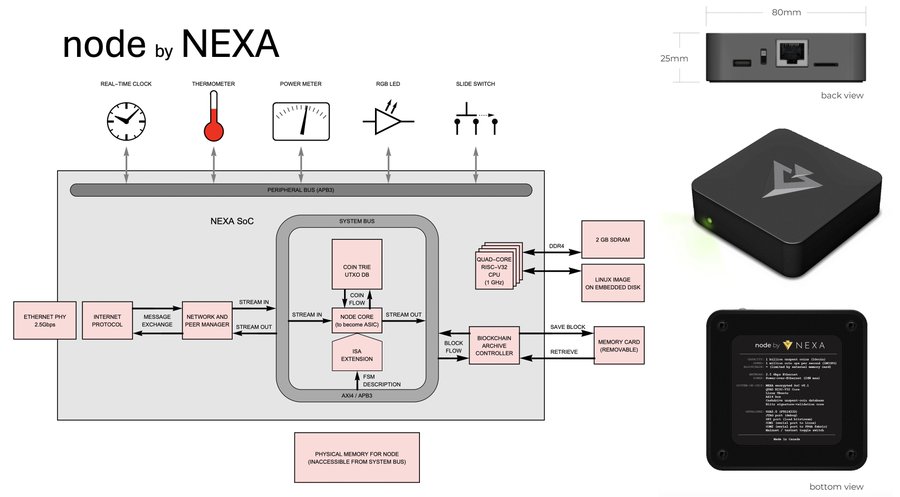
Fig. 17. FPGA-based hardware node.
The heart of the node is the Nexa System-on-Chip (SoC). In addition to a large amount of reconfigurable FPGA fabric, this SoC contains a quad-core RISC-V processor running at 1 GHz, which boots into Linux. But the idea is not to actually use Linux for the full node. We want to get to the point where the full node exists purely in hardware (the FPGA fabric + a future ASIC), so transactions come in over the network, are routed through our hardware transaction pipeline, and solved blocks are written to the memory card, without any intervention by the operating system. This way, the data pipelines remain purely in the hardware domain where they are very fast. From the Linux perspective, the hardware node is a “device” in the Linux device tree. Wallet software running on the Linux side could talk to the hardware node to get updates on balances, or to broadcast transactions into the network. This truly is a cryptocurrency computer.
Nexa versus Ethereum
People ask “what is the difference between Nexa and Ethereum?” Both have flexible scripting systems, but the underlying architectures are very different.
Nexa uses the same UTXO model as bitcoin. There are no accounts. There are only coins. And a coin can either be spent in full or not at all. A typical transaction is shown on the left side of Fig. 18. The transaction specifies the input coins that will be spent, provides signatures which authorize that spending, and specifies the list of the new coins to be minted. If this transaction executes, the two pink coins in Fig. 18 will be removed from the UTXO set and these three green coins will be added. This architecture is nice because the changes to the “global state” are localized to the specified inputs of the transactions. This localization allows for parallelism. We can have multiple heads checking multiple transactions and there will be no conflicts because we know ahead of time the region of state-space that each transaction can modify. The UTXO model is highly scalable because it is highly parallelizable.
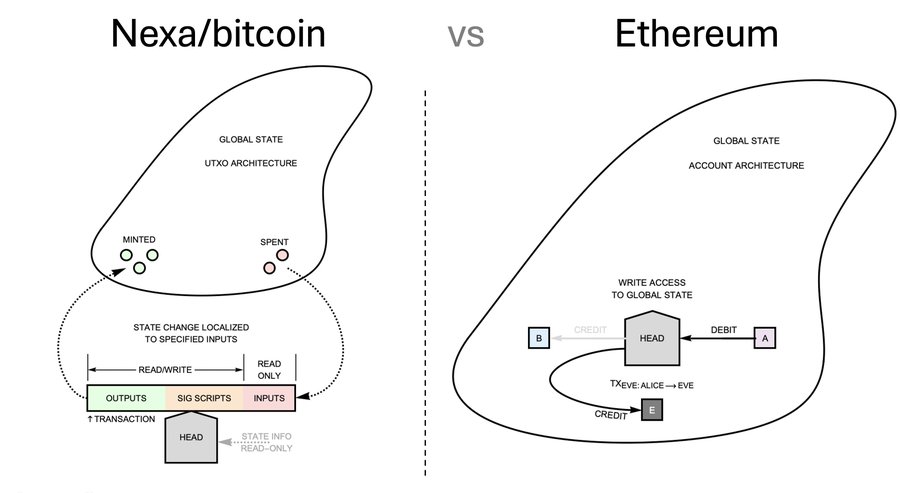
Fig. 18. UTXO architecture versus account architecture.
Ethereum is very different because it uses an account-based model. You can imagine that the “head” is inside the global state-space and has read and write access to everything. This makes Ethereum more flexible, but it can also lead to unexpected behaviour. For example, Alice could write a transaction that debits her account and credit Bob’s account. But maybe, if the contracts are confusing (as they often are), Eve can write a transaction that debits Alice’s account and credits Eve’s account! This is not possible in Bitcoin or Nexa because the inputs are essentially firewalled. If you’ve understood my talk you can probably see that the Ethereum model won’t be parallelizable like the UTXO model, because the region of state-space that a transaction can interact cannot be localized like it can in Bitcoin.
I’m not saying Nexa is better than Ethereum. Instead, they are two completely different things that serve different purposes. Here’s how I look at it:
- In Nexa, miners compete via proof-of-work to confirm recent transactions in a block
- Global state access is NOT necessary because a coin can only be spent by its owner.
- Nex is a chunk of a digital commodity
- In Ethereum, shareholders vote via proof-of-stake on which global state changes to permit.
- Global state access is necessary to execute any possible shareholder resolution
- Ether is a share in a decentralized company, not a digital commodity like Bitcoin or Nexa.
Thank you for listening.
NOTES
- The only scaling limitation I’ve found is due to the race-condition where two validation engines might attempt to spend the same coin at the same time: the “clock inversion” solution I described generalizes to multiplying the UTXO database clock frequency by the number of parallel validation engines. But this breaks down once clock frequencies get into the gigahertz range due to semiconductor physics (e.g., we cannot clock a circuit faster than the underlying signals can propagate, and signal propagation is limited by the speed of light). I think there is a probably a physics-based scaling limit of a few billion transactions per second for UTXO-based cryptocurrencies.
- This set is actually redundant: with only the NOT gate and the AND gate, the other four gates can be constructed (including the flip-flop). In fact, any gate can be constructed using only NAND gates (a NAND gate is an AND gate with an inverted output)!
- More about the the compact bitwise prefix trie:
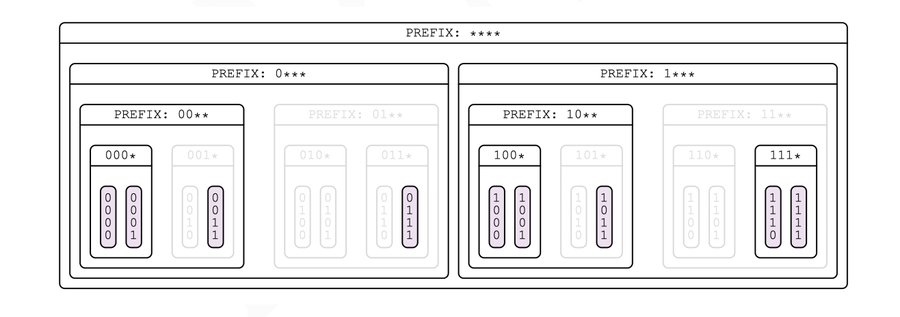
Binning by the binary prefix of the keys can be extended, resulting in a nested structure of bins, shown here for a four-bit key space. Each bin in the last row can only hold two key/value pairs—one with a key that matches the bin’s prefix with a least significant bit of 0 and the other with a key that matches the bin’s prefix with a least significant bit of 1. Removing all bins with fewer than two items (those that are grayed out) results in a structure that can be physically constructed for large key spaces. Exactly N-1 bins are required, where N is the number of key/value pairs.
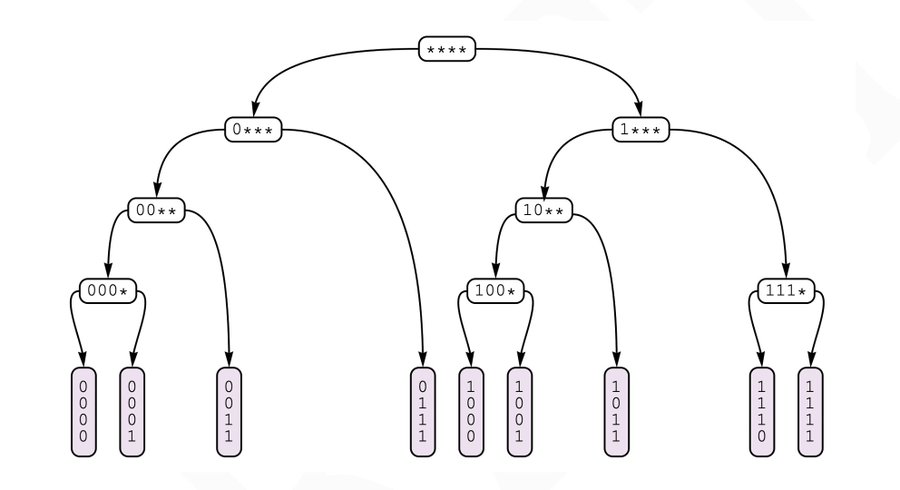
An alternative view of a compact bitwise prefix trie. The horizontal ovals are interior nodes, and point to right and left subtries and describe the binary prefix common to elements in both. The purple leaf nodes contain the key/value pairs.
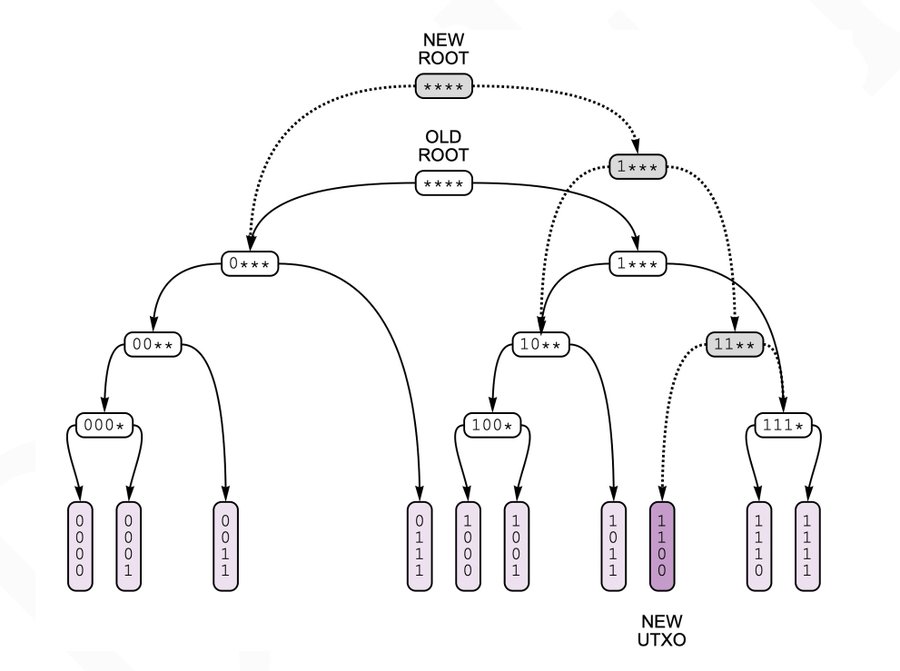
A new key/value pair can be added or removed in a way that leaves the previous trie intact, by adding only a single new branch. In the illustration above, an entry with key 1100 is added to the trie by adding the branch shaded in gray. The previous state of the trie (before 1100 was added) persists and is accessible via the trie’s old root.
Original article: